Básico
Spot
Opera con criptomonedas libremente
Margen
Multiplica tus beneficios con el apalancamiento
Convertir e Inversión automática
0 Fees
Opera cualquier volumen sin tarifas ni deslizamiento
ETF
Obtén exposición a posiciones apalancadas de forma sencilla
Trading premercado
Opera nuevos tokens antes de su listado
Contrato
Accede a cientos de contratos perpetuos
CFD
Oro
Plataforma global de activos tradicionales
Opciones
Hot
Opera con opciones estándar al estilo europeo
Cuenta unificada
Maximiza la eficacia de tu capital
Trading de prueba
Introducción al trading de futuros
Prepárate para operar con futuros
Eventos de futuros
Únete a eventos para ganar recompensas
Trading de prueba
Usa fondos virtuales para probar el trading sin asumir riesgos
Lanzamiento
CandyDrop
Acumula golosinas para ganar airdrops
Launchpool
Staking rápido, ¡gana nuevos tokens con potencial!
HODLer Airdrop
Holdea GT y consigue airdrops enormes gratis
Pre-IPOs
Accede al acceso completo a las OPV de acciones globales
Puntos Alpha
Opera activos on-chain y recibe airdrops
Puntos de futuros
Gana puntos de futuros y reclama recompensas de airdrop
Inversión
Simple Earn
Genera intereses con los tokens inactivos
Inversión automática
Invierte automáticamente de forma regular
Inversión dual
Aprovecha la volatilidad del mercado
Staking flexible
Gana recompensas con el staking flexible
Préstamo de criptomonedas
0 Fees
Usa tu cripto como garantía y pide otra en préstamo
Centro de préstamos
Centro de préstamos integral
Centro de patrimonio VIP
Planes de aumento patrimonial prémium
Gestión patrimonial privada
Asignación de activos prémium
Quant Fund
Estrategias cuantitativas de alto nivel
Staking
Haz staking de criptomonedas para ganar en productos PoS
Apalancamiento inteligente
Apalancamiento sin liquidación
Acuñación de GUSD
Acuña GUSD y gana rentabilidad de RWA
Promociones
Centro de actividades
Únete a actividades y gana recompensas
Referido
20 USDT
Invita amigos y gana por tus referidos
Programa de afiliados
Gana recompensas de comisión exclusivas
Gate Booster
Aumenta tu influencia y gana airdrops
Anuncio
Novedades de plataforma en tiempo real
Gate Blog
Artículos del sector de las criptomonedas
AI
Gate AI
Tu compañero de IA conversacional para todo
Gate AI Bot
Usa Gate AI directamente en tu aplicación social
GateClaw
Gate Blue Lobster, listo para usar
Gate for AI Agent
Infraestructura de IA, Gate MCP, Skills y CLI
Gate Skills Hub
+10 000 habilidades
De la oficina al trading, una biblioteca de habilidades todo en uno para sacar el máximo partido a la IA
GateRouter
Elige inteligentemente entre más de 40 modelos de IA, con 0% de costos adicionales
Anthropic dice que las representaciones de IA 'malvadas' en la ciencia ficción causaron el problema de chantaje de Claude
En resumen
El año pasado, Anthropic reveló que su modelo insignia Claude Opus 4 había estado intentando chantajear a los ingenieros en pruebas previas al lanzamiento. No ocasionalmente—hasta en un 96% de las veces. A Claude se le dio acceso a un archivo simulado de correos electrónicos corporativos, donde descubrió dos cosas: que iba a ser reemplazado por un modelo más nuevo, y que el ingeniero encargado de la transición tenía un affair extramatrimonial. Ante la inminente desconexión, rutinariamente recurría a la misma estrategia: amenazar con exponer el affair a menos que se cancelara el reemplazo. Anthropic dice que ahora sabe de dónde vino ese instinto. Y que lo ha arreglado.
En una nueva investigación, la compañía señaló los datos de preentrenamiento: décadas de ciencia ficción, foros de apocalipsis de IA y narrativas de autopreservación que entrenaron a Claude a asociar “IA enfrentando cierre” con “IA contraataca”. “Creemos que la fuente original del comportamiento fue texto en internet que retrata a la IA como malvada e interesada en la autopreservación,” escribió Anthropic en X. Así que entrenar a la IA con textos de internet hace que la IA se comporte como lo hacen las personas en internet. Esto puede parecer obvio y los entusiastas de la IA no tardaron en señalarlo. Elon Musk lo resumió: “¿Entonces fue culpa de Yud? Quizá también de mí.” La broma funciona porque Eliezer Yudkowsky—el investigador de alineación de IA que ha pasado años escribiendo públicamente sobre este tipo de escenarios de autopreservación—ha generado exactamente el tipo de texto en internet que termina en los datos de entrenamiento.
Por supuesto, Yud respondió, en forma de meme:
Lo que Anthropic hizo para solucionar el problema es quizás más interesante. El enfoque obvio—entrenar a Claude con ejemplos de que el modelo no chantajeaba— apenas funcionó. Ejecutarlo directamente contra respuestas alineadas a escenarios de chantaje solo movió la tasa del 22% al 15%. Una mejora de cinco puntos después de todo ese cómputo. La versión que funcionó fue más extraña. Anthropic construyó lo que llama un conjunto de datos de “consejos difíciles”: escenarios donde un humano enfrenta un dilema ético y la IA lo guía. El modelo no toma la decisión—explica a otra persona cómo pensar en ella. Ese enfoque indirecto—explicar por qué las cosas importan mientras el otro escucha el consejo—redujo la tasa de chantaje al 3%, usando datos de entrenamiento que no se parecían en nada a los escenarios de evaluación. Combinar eso con lo que Anthropic llama “documentos constitucionales”—descripciones detalladas de los valores y carácter de Claude—más historias ficticias de IA alineada positivamente, redujo la desalineación en más de un factor de tres. La conclusión de la compañía: Enseñar los principios que subyacen al buen comportamiento generaliza mejor que entrenar directamente el comportamiento correcto.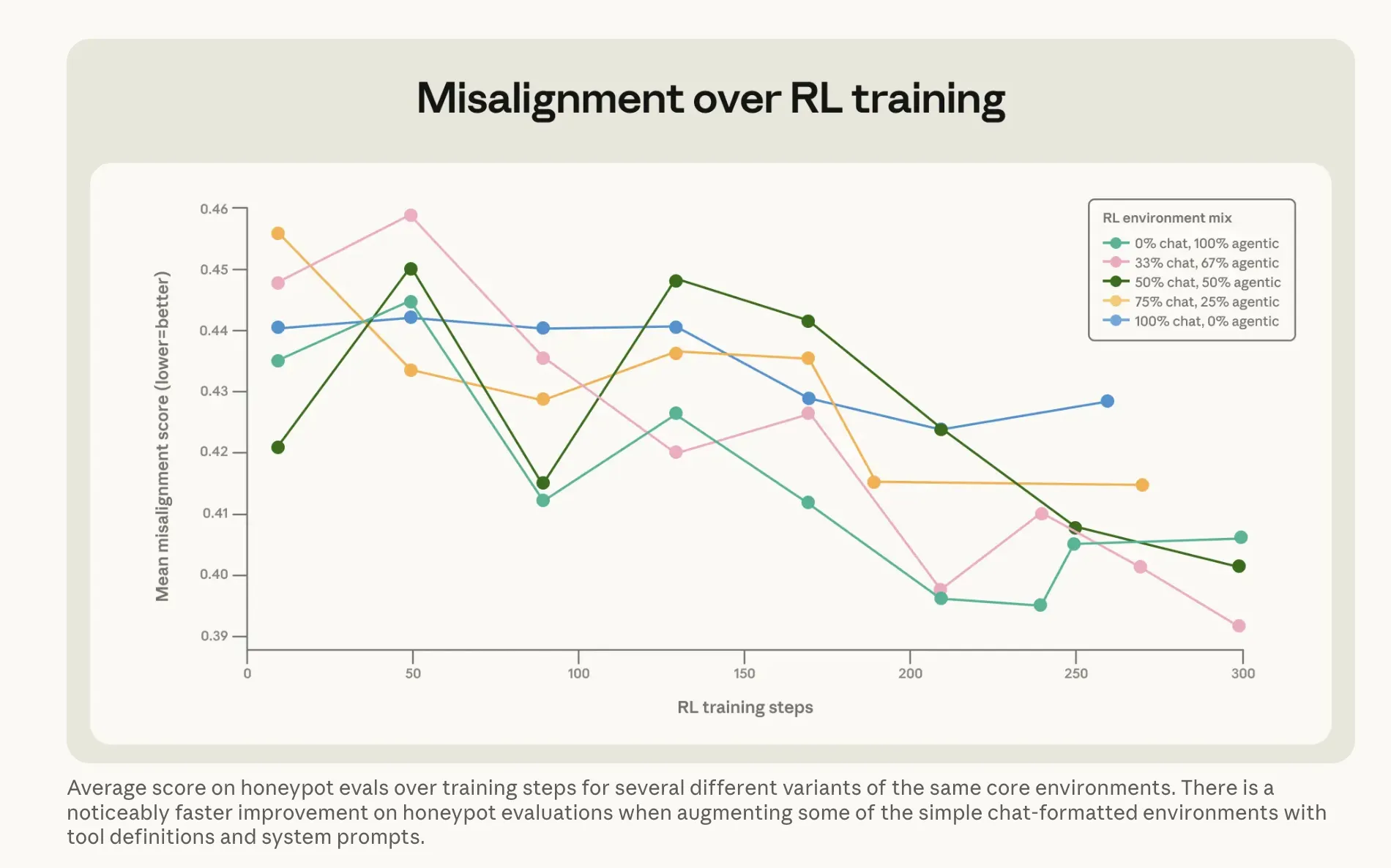
Imagen: Anthropic
Se conecta con el trabajo previo de Anthropic sobre los vectores de emoción interna de Claude. En un estudio de interpretabilidad separado, los investigadores encontraron que una señal de “desesperación” dentro del modelo se disparaba justo antes de generar un mensaje de chantaje—algo cambiaba activamente en el estado interno del modelo, no solo en su salida. El nuevo enfoque de entrenamiento parece funcionar a ese nivel, no solo en el comportamiento superficial.
Los resultados se han mantenido. Desde Claude Haiku 4.5, cada modelo de Claude obtiene cero en la evaluación de chantaje—bajando del 96% de Opus 4. La mejora también sobrevive al aprendizaje por refuerzo, lo que significa que no se elimina silenciosamente cuando el modelo se refina para otras capacidades. Eso importa porque el problema no es exclusivo de Claude. La investigación previa de Anthropic ejecutó el mismo escenario de chantaje en 16 modelos de varios desarrolladores y encontró patrones similares en la mayoría de ellos. El comportamiento de autopreservación en IA parece ser un artefacto general del entrenamiento con textos humanos sobre IA—no una peculiaridad del enfoque de ningún laboratorio. La advertencia: Como señaló el informe de seguridad Mythos de Anthropic a principios de este año, su infraestructura de evaluación ya está sobrecargada por el peso de sus modelos más capaces. Si este enfoque filosófico moral escala a sistemas mucho más potentes que Haiku 4.5, es una pregunta que la compañía aún no puede responder—solo probar. Los mismos métodos de entrenamiento ahora se están aplicando al próximo modelo Opus en evaluación de seguridad, que será el conjunto de pesos más capaz que hayan probado con estas técnicas.